AI Explained
Plain explanations of trending AI concepts, with live visualizations.
MaxProof clears IMO/USAMO gold — Defense-in-depth generative verifier — What does it mean?
MaxProof tunes its proof verifier for a very low false-positive rate, so sampling many candidate proofs and picking a winner by tournament actually works.

A survey of agent-environment engineering — Symbolic vs neural environment synthesis — What does it mean?
A survey reframes building an agent's training world as engineering — and its sharpest split is hand-coded vs model-generated environments.

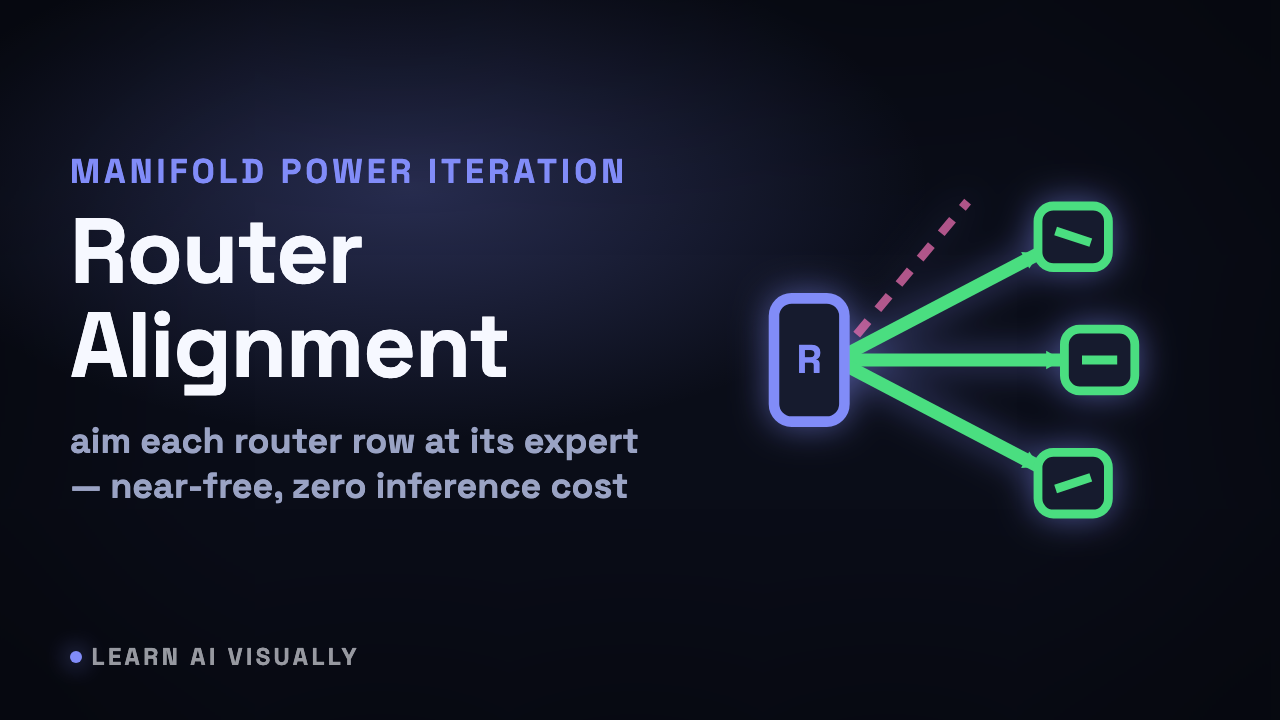
Manifold Power Iteration redesigns MoE routers — Router-to-expert alignment — What does it mean?
Manifold Power Iteration rotates each MoE router row onto its expert's top singular direction — better routing at 0.2% train cost, zero inference overhead.
CodeSpear strips an LLM's ability to refuse — Grammar-constrained decoding jailbreak — What does it mean?
Force an LLM's output to fit a code grammar and its natural-language refusal becomes invalid — CodeSpear uses this to lift attack success to ~82%.

Workflow-GYM scores computer-use agents at ~30% on pro tasks — End-to-end GUI workflow completion — What does it mean?
Workflow-GYM drops computer-use agents into real pro software and grades the whole multi-stage job end to end — SOTA clears only ~30%.

Role-Agent paper — One LLM as agent and environment — What does it mean?
Role-Agent trains an agent by making one LLM play both the agent and the world it acts in — no external environment, no separate reward model.

Kwai Keye-VL-2.0 — DeepSeek Sparse Attention for video — What does it mean?
Keye-VL-2.0 ports DeepSeek Sparse Attention to video: a cheap 'lightning indexer' picks the few frames each query needs, keeping a 256K context lossless.

DRPO: smooth trust-region regularizer replaces hard masks in LLM RL — Corrective gradients past the boundary — What does it mean?
DRPO swaps RL's hard trust-region mask for a smooth, advantage-weighted penalty — a diverging token gets pulled back, not dropped.

SearchSwarm hits SOTA on BrowseComp with a 30B agent — Distilling delegation into the weights — What does it mean?
SearchSwarm bakes task decomposition and subagent delegation into a 30B model's weights via SFT — not prompts — and tops BrowseComp.

Reasoning Arena adds trace tournaments where RL verifiable rewards tie — Bradley-Terry trace ranking — What does it mean?
Reasoning Arena breaks RLVR reward ties by judging tied reasoning traces in a pairwise tournament and ranking them with a Bradley-Terry model.

Google releases DiffusionGemma — Parallel block decoding — What does it mean?
DiffusionGemma writes text by refining a whole block of 256 tokens at once — parallel block decoding, up to 4x faster than autoregressive Gemma.

Anthropic's Claude Fable 5 & Mythos 5 — Safety-routing fallback classifiers — What does it mean?
Fable 5 ships a frontier model to everyone by routing under 5% of sensitive requests to a more conservative model instead of weakening it.
