AI Explained
Plain explanations of trending AI concepts, with live visualizations.
MultiHashFormer drops the vocab-sized embedding table — Hash-signature token representation — What does it mean?
A new LM names each token by a short multi-hash signature instead of a vocab-sized embedding row, decoupling parameters from vocabulary size.

Cluster-Route-Escalate cascade serves LLMs at 97-99% accuracy for less cost — Cost-aware LLM cascade — What does it mean?
A cascade routes each query to the cheapest capable model and escalates only weak answers to a stronger one: 97-99% accuracy at lower cost.

SGLang v0.5.14 — LPLB expert-parallel load balancing — What does it mean?
SGLang v0.5.14's LPLB solves a tiny linear program each step to even MoE token load across GPUs, so the busiest GPU stops gating throughput.

ViQ: text-aligned visual tokens, quantized at any image resolution — Text-aligned quantized visual tokens vs continuous patches — What does it mean?
ViQ turns images into discrete, text-aligned visual tokens — like a fixed vocabulary of labeled stamps — so a multimodal LLM reads pictures the way it reads words, at any resolution.

RL data scheduler hits target perplexity with 44% fewer pretraining steps — RL-learned data mixture vs fixed pretraining blend — What does it mean?
An RL agent adjusts an LLM's pretraining data mixture on the fly instead of using a fixed blend, hitting target perplexity with 44% fewer steps.

InfoKV: entropy-aware KV-cache compression keeps long-context recall — Forward Influence — What does it mean?
InfoKV compresses the KV cache by a token's predictive uncertainty, not attention alone — keeping the unsure tokens that steer distant context.

JetSpec speeds speculative decoding up to 9.64× — Parallel tree drafting — What does it mean?
JetSpec drafts a tree of candidate tokens in one pass, turning a bigger draft budget into longer accepted runs — up to 9.64× faster decode.

WorldKV — Evict-and-reinsert KV memory — What does it mean?
WorldKV evicts KV chunks to camera-indexed storage and reinserts them on revisit, bounding a video world model's cache at ~2x throughput.

MiniMax-M2 ships a 230B open MoE with 40× faster RL training — Forge RL prefix-tree merging — What does it mean?
MiniMax-M2's Forge RL merges rollouts that share an opening into one tree, so the shared work runs once — a reported 40× training speedup.

Grouped Query Experts puts mixture-of-experts routing inside attention — Query-head expert routing — What does it mean?
Grouped Query Experts adds a per-token router that turns on only a few of attention's query heads — keeping every key-value head dense, so the KV cache is unchanged.

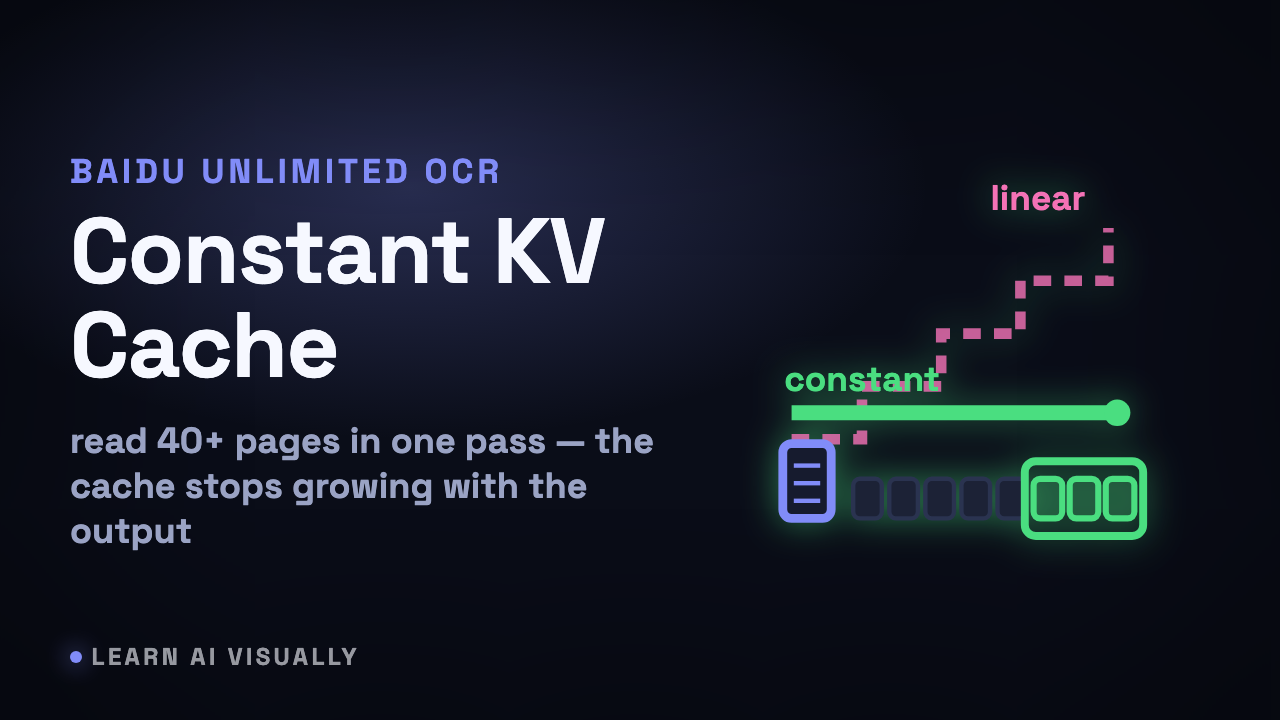
Baidu Unlimited OCR holds the KV cache constant for 40+ pages — Reference Sliding Window Attention — What does it mean?
Baidu's Unlimited OCR swaps decoder attention for R-SWA — each token reads the whole document plus only the last 128 outputs — so the KV cache stays constant across 40+ pages.
GLM-5.2 becomes the top open-weights model — Active vs total parameters — What does it mean?
GLM-5.2 lists 744B total but 40B active parameters — two numbers that decode different costs: the memory you hold vs the compute you pay per token.
