AI Explained
Plain explanations of trending AI concepts, with live visualizations.
VibeThinker-3B hits 94.3 on AIME 2026 — Diversity-driven RL — What does it mean?
Diversity-driven RL keeps a model's solution strategies wide instead of collapsing onto a few — how a 3B model reaches 94.3 on AIME 2026.

AdaSR teaches LLMs to reason mid-stream — Streaming reasoning — What does it mean?
AdaSR trains LLMs to reason while input still streams in, then deliberate once it lands — split-phase RL credit under a latency-aware reward.

VIA-SD speeds up speculative decoding 10–20% — Tiered confidence-gated verification — What does it mean?
VIA-SD adds a confidence-gated middle tier to speculative decoding — close calls go to a slim sub-network of the same model, not a full re-run.

MaxProof clears IMO/USAMO gold — Defense-in-depth generative verifier — What does it mean?
MaxProof tunes its proof verifier for a very low false-positive rate, so sampling many candidate proofs and picking a winner by tournament actually works.

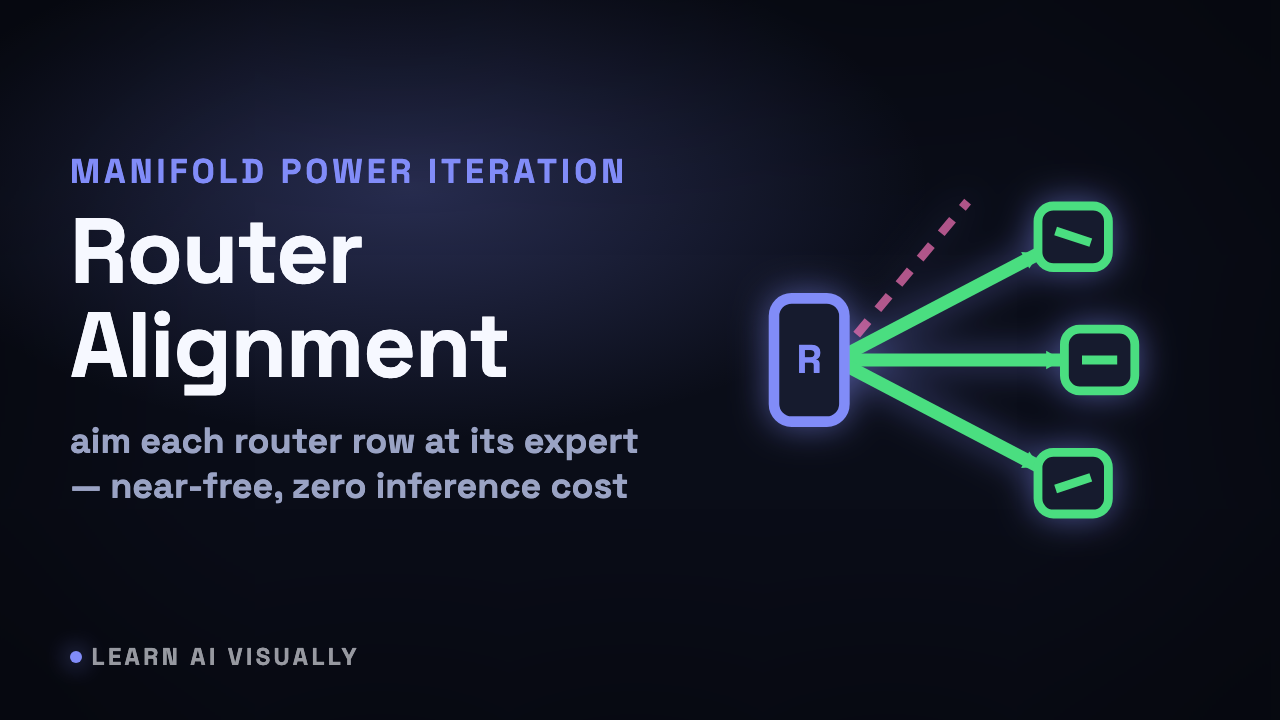
Manifold Power Iteration redesigns MoE routers — Router-to-expert alignment — What does it mean?
Manifold Power Iteration rotates each MoE router row onto its expert's top singular direction — better routing at 0.2% train cost, zero inference overhead.
CodeSpear strips an LLM's ability to refuse — Grammar-constrained decoding jailbreak — What does it mean?
Force an LLM's output to fit a code grammar and its natural-language refusal becomes invalid — CodeSpear uses this to lift attack success to ~82%.

Kwai Keye-VL-2.0 — DeepSeek Sparse Attention for video — What does it mean?
Keye-VL-2.0 ports DeepSeek Sparse Attention to video: a cheap 'lightning indexer' picks the few frames each query needs, keeping a 256K context lossless.

DRPO: smooth trust-region regularizer replaces hard masks in LLM RL — Corrective gradients past the boundary — What does it mean?
DRPO swaps RL's hard trust-region mask for a smooth, advantage-weighted penalty — a diverging token gets pulled back, not dropped.

Reasoning Arena adds trace tournaments where RL verifiable rewards tie — Bradley-Terry trace ranking — What does it mean?
Reasoning Arena breaks RLVR reward ties by judging tied reasoning traces in a pairwise tournament and ranking them with a Bradley-Terry model.

Google releases DiffusionGemma — Parallel block decoding — What does it mean?
DiffusionGemma writes text by refining a whole block of 256 tokens at once — parallel block decoding, up to 4x faster than autoregressive Gemma.

Attention Amnesia: CoT fine-tuning wrecks long-range recall in hybrid LLMs — Training-free QK-Restore — What does it mean?
Fine-tuning a hybrid LLM to reason silently breaks long-range recall; QK-Restore rolls back just the Q/K projections to recover it — no retraining.

Latent Context LMs compress prompts 16x — Encoder-decoder prompt compression — What does it mean?
Latent Context LMs use a small encoder to squeeze a long prompt into a 16x shorter sequence of latent embeddings a decoder reads as tokens.
