AI Explained
Plain explanations of trending AI concepts, with live visualizations.
Taylor-Calibrate cuts hybrid-attention distillation tokens 4.9–9.2× — Taylor-guided gate initialization — What does it mean?
Taylor-Calibrate presets a linear-attention student's gates from the teacher — hitting distillation targets with 4.9–9.2× fewer tokens.

HydraHead fuses full and linear attention per head, not per layer — Head-axis attention hybridization — What does it mean?
HydraHead mixes full and linear attention head-by-head, keeping exact attention only for retrieval-critical heads — a 7:1 split matching a coarser 3:1.

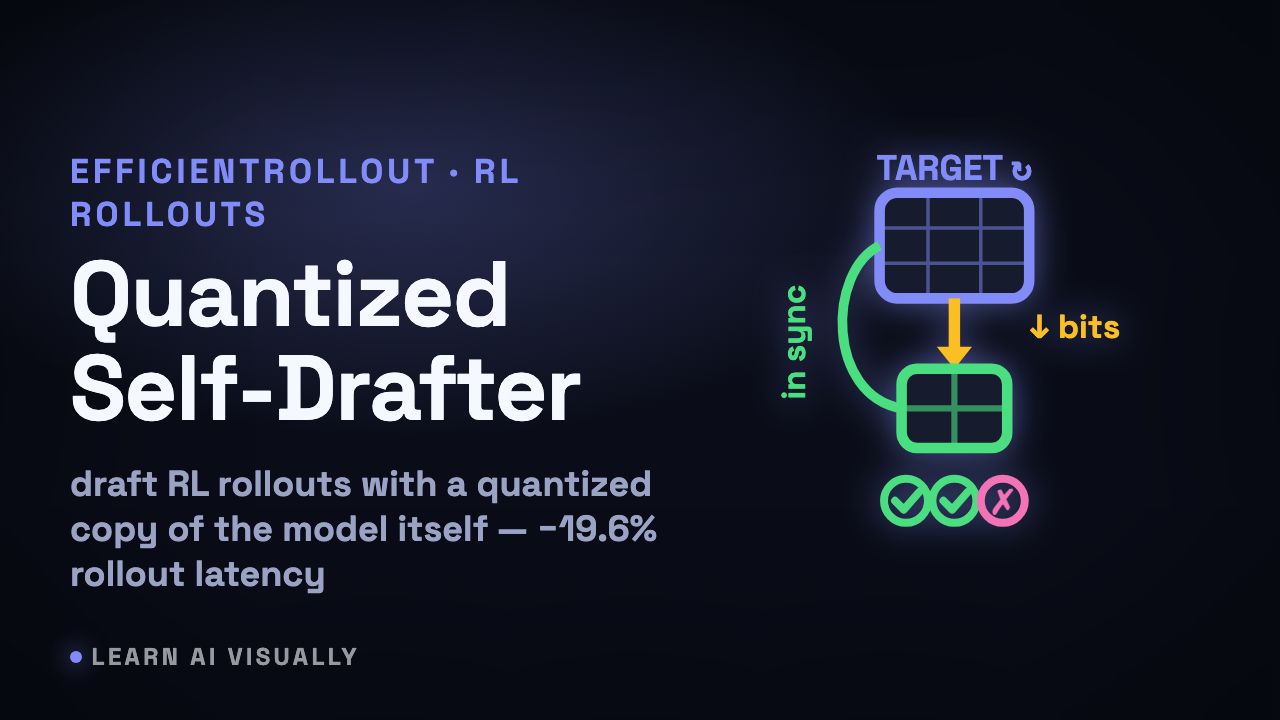
EfficientRollout — Self-speculative decoding with quantized self-drafters — What does it mean?
EfficientRollout speeds RL rollouts by drafting with a quantized copy of the model itself — a self-drafter that tracks the evolving policy for free.
CacheWeaver reorders RAG evidence for prefix-cache reuse — Prefix-cache-aware evidence reordering — What does it mean?
CacheWeaver reorders the retrieved chunks in a RAG prompt so the serving engine reuses its KV prefix cache — cutting median TTFT 20–33% with no measured quality loss.

LoopCoder-v2: two loops of a shared block beat deeper looping — Weight-tied block looping — What does it mean?
Running one shared transformer block twice lifts a 7B model from 43.0 to 64.4 on SWE-bench — but three or more loops regress, a non-monotonic sweet spot.

ConSA learns where to put full vs sliding-window attention per head — Controllable attention sparsity — What does it mean?
ConSA learns, under a fixed budget, which attention heads get full attention and which get a cheap sliding window — instead of hand-coded rules.

AnchorKV makes KV-cache compression safety-aware — Refusal anchor in the KV cache — What does it mean?
AnchorKV gives KV-cache eviction a safety-aware penalty, so compressing the cache to save memory no longer quietly erodes a model's alignment.

AMD ATOM + ATOMesh — Prefill/decode disaggregation on ROCm — What does it mean?
AMD's new ROCm serving stack splits LLM inference into a compute-bound prefill phase and a memory-bound decode phase, running each on its own pool of GPUs.

Variable-width transformers cut FLOPs 22% — Hourglass layer width — What does it mean?
A transformer with wide outer layers and a narrow middle — an hourglass — cuts 22% of FLOPs and 15% of KV-cache at matched loss.
Ternary Mamba compresses an SSM 3.6x with 4 GPU-hours of QAT — Ternary quantization-aware training — What does it mean?
Ternary Mamba forces every weight to -1, 0, or +1 and trains on that grid, shrinking a Mamba SSM 3.6x in 4 GPU-hours.

SoftMoE replaces top-k expert routing — Differentiable soft top-k routing — What does it mean?
SoftMoE swaps a mixture-of-experts' hard top-k router for a differentiable soft top-k, so the router learns straight from the task loss.

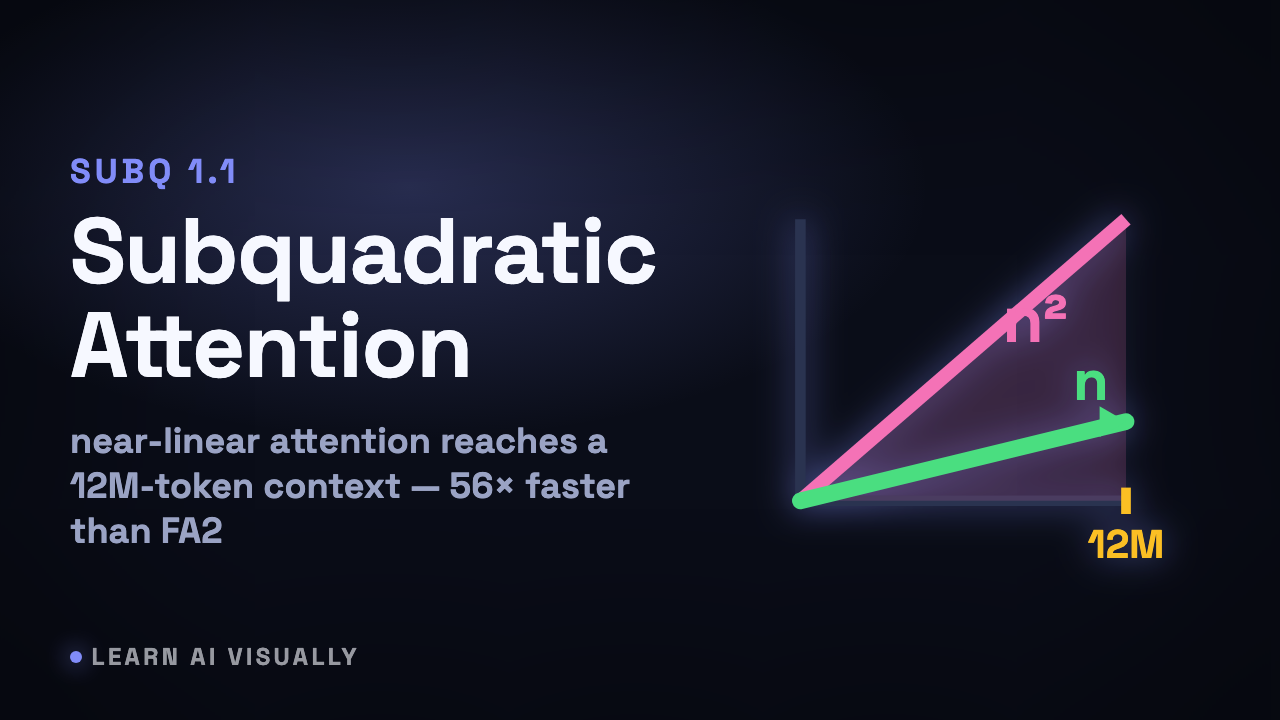
SubQ 1.1 Small hits a 12M-token context — Subquadratic sparse attention — What does it mean?
SubQ 1.1 trades dense n² attention for a near-linear sparse form — a 12M-token context, 56× faster than FlashAttention-2 at 1M.