AI Explained
Plain explanations of trending AI concepts, with live visualizations.
S-Agent: spatial tool-use makes an 8B agent rival GPT-5.4 on spatial reasoning — Spatio-temporal evidence accumulation — What does it mean?
S-Agent makes a VLM a planner directing tools to build one shared 3-D model of a scene — an 8B agent then rivals GPT-5.4.

Multi-LCB extends LiveCodeBench to 12 languages — Cross-language generalization gap — What does it mean?
Multi-LCB ports each LiveCodeBench task into 12 languages with one judge, so a score drop measures pure cross-language generalization.

GateMem shows agent memory can't balance utility, access control, and forgetting — Memory governance trilemma — What does it mean?
GateMem benchmarks shared agent memory on utility, access control, and reliable forgetting at once — and finds no method passes all three.

ContextRL rewards evidence selection to boost agent and multimodal reasoning — Contrastive context-selection RL — What does it mean?
ContextRL rewards a model for picking which of two near-identical contexts supports the answer — sharpening fine-grained evidence grounding.

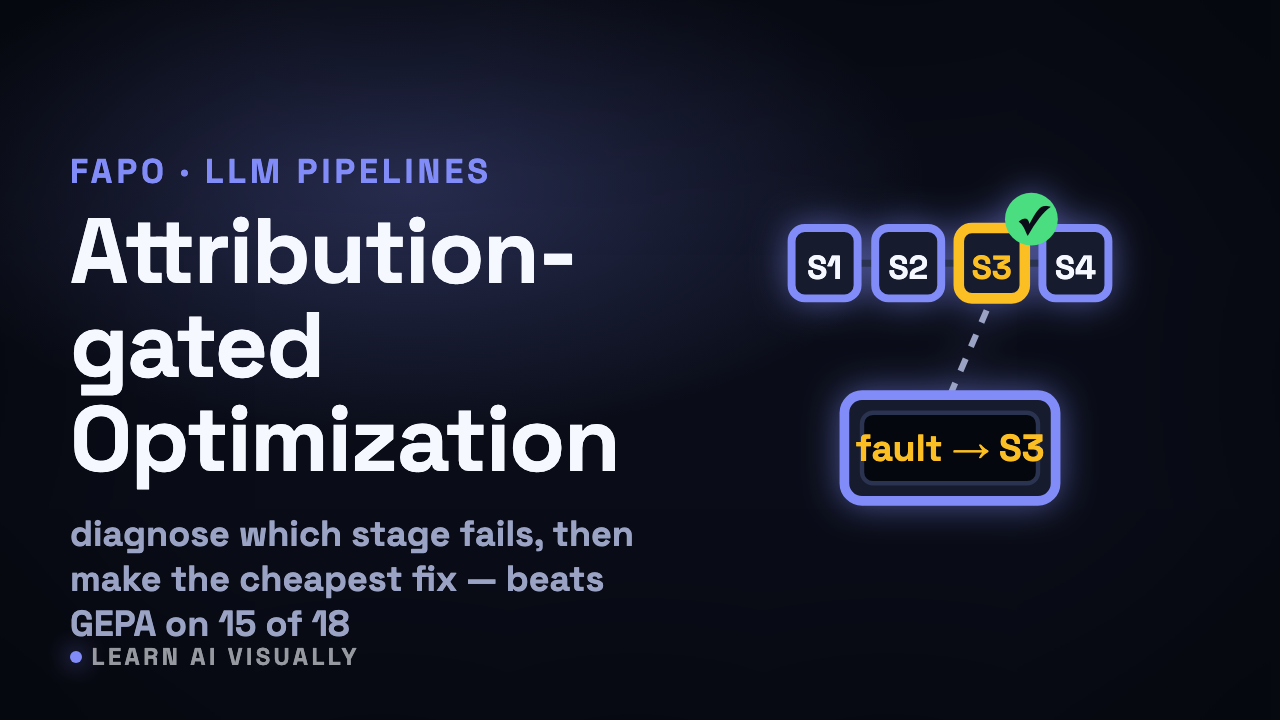
FAPO auto-optimizes multi-step LLM pipelines, beating GEPA on 15 of 18 benchmarks — Failure-attribution-gated prompt optimization — What does it mean?
FAPO has Claude Code diagnose where an LLM pipeline fails, then make scoped prompt or chain edits — beating GEPA on 15 of 18 benchmarks.
AtomMem gives LLM agents memory built from atomic facts, SOTA on LoCoMo — Atomic-fact agent memory — What does it mean?
AtomMem distills an agent's long history into atomic facts, files them by event and time, and links them in an associative graph for retrieval.

LedgerAgent gives tool-calling agents a structured state ledger — Pre-tool-call policy validation — What does it mean?
LedgerAgent tracks an agent's task state in a separate ledger and checks domain policy against it before any irreversible tool call.

Agent leaderboards mislead under distribution shift (IBM) — Predictive validity — What does it mean?
IBM: agent leaderboards rank models by one aggregate score that fails under distribution shift — measure predictive validity instead.

PreAct compiles agent runs into replayable programs — Compiled trajectory replay — What does it mean?
PreAct compiles an agent's successful run into a replayable program it re-runs with no per-step model call — 8.5–13× faster on repeats.

Microsoft FastContext: a repo-explorer subagent cuts coding-agent tokens 60% — Explorer-subagent context offloading — What does it mean?
FastContext trains a separate read-only explorer subagent that finds code and returns citations, cutting a coding agent's tokens up to 60%.

SIMMER: 56% of frontier-LLM plans hide latent failures — Latent failures in planning — What does it mean?
A latent failure is a plan that runs to the end without erroring and still silently fails the goal — SIMMER finds up to 56% of LLM plans hide one.

CacheRL trains tool-calling agents via cached rollouts at 100× less compute — Cached rollouts for agent RL — What does it mean?
CacheRL replaces live tool execution during RL rollouts with a three-tier fuzzy cache — 92% process accuracy vs GPT-5's 94% at ~100× less compute.
