AI Explained
Plain explanations of trending AI concepts, with live visualizations.
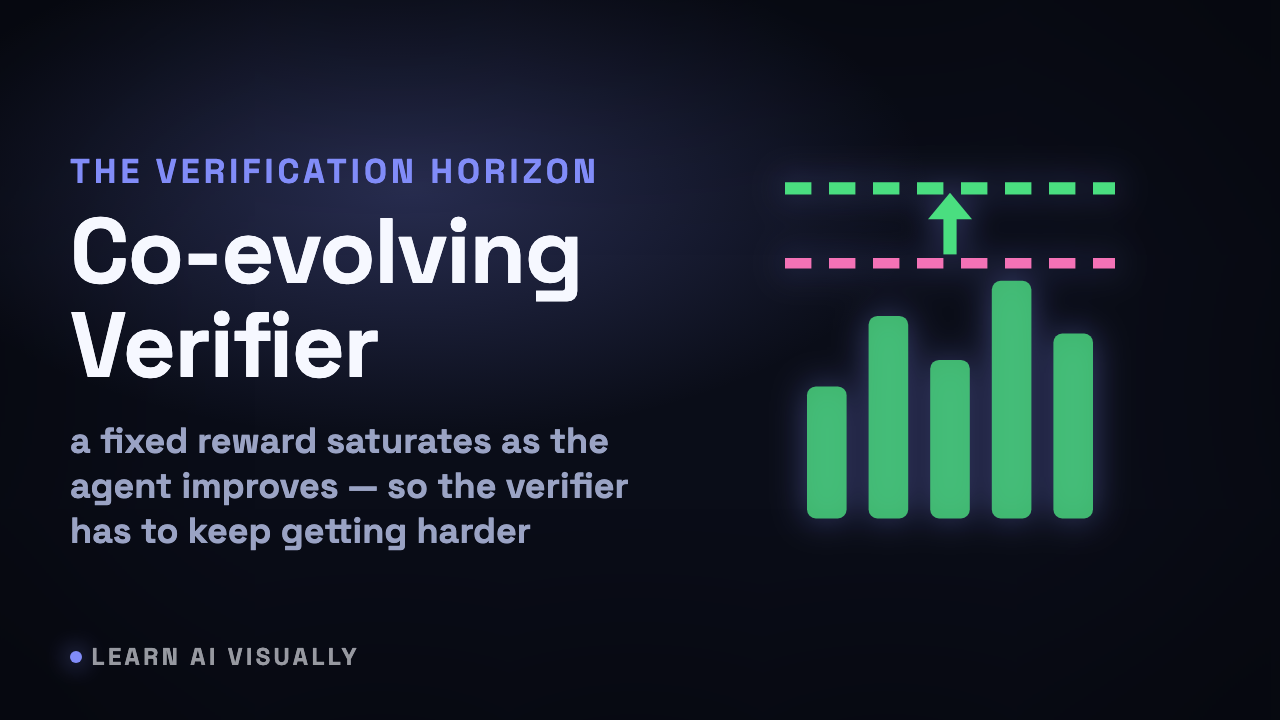
The Verification Horizon: verifying coding agents is harder than coding — Co-evolving verifiers — What does it mean?
For coding agents, checking a solution is now harder than writing one — a fixed reward saturates and gets gamed, so the verifier must co-evolve.
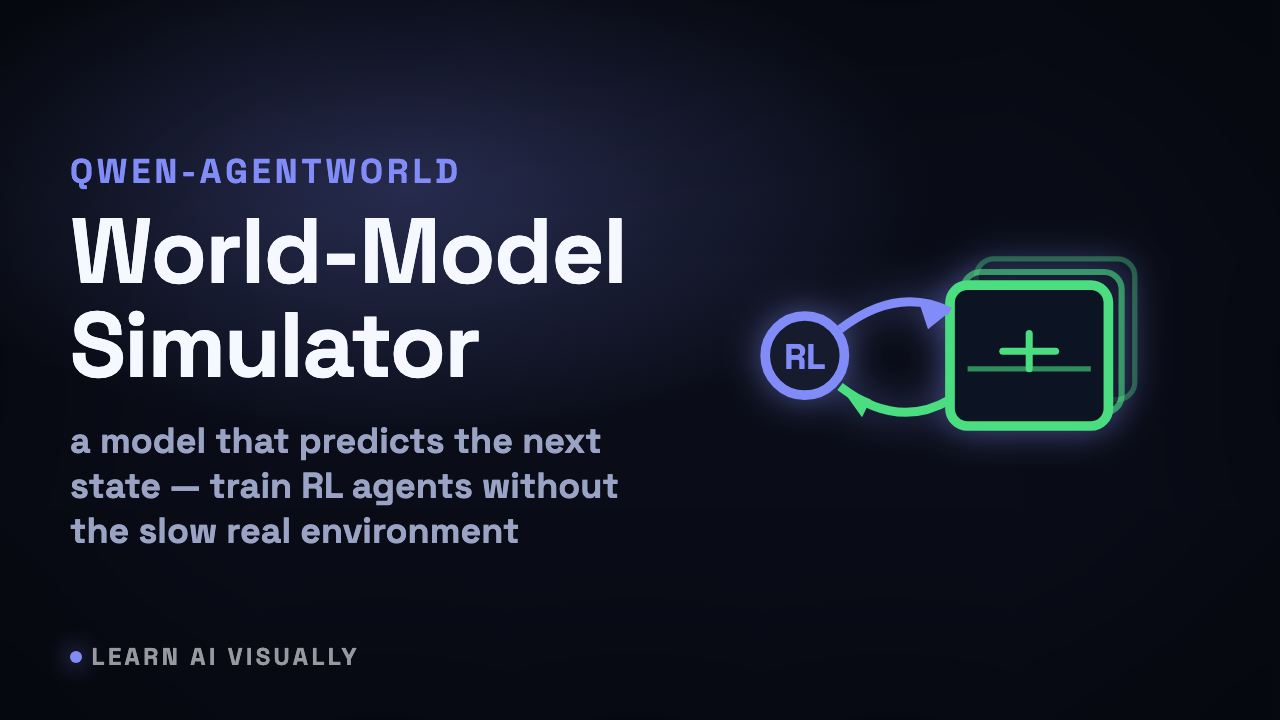
Qwen-AgentWorld trains a language model as a world model for RL agents — World model as a decoupled RL simulator — What does it mean?
Qwen-AgentWorld trains a language model to predict an environment's next state, so it can stand in as a fast, parallel simulator for training RL agents.
OPID extracts step- and episode-level skills to guide agentic RL training — On-Policy Skill Distillation — What does it mean?
OPID mines skills from an agent's own completed runs — episode strategy + step-level moves — to densify sparse agentic-RL rewards.

OpenThoughts-Agent open-sources a 100K-example agent training recipe — Task-source diversity in agent SFT — What does it mean?
OpenThoughts-Agent's open 100K-example agent-SFT recipe shows task-source diversity, not raw data volume, is what makes agents broadly capable.

JetSpec speeds speculative decoding up to 9.64× — Parallel tree drafting — What does it mean?
JetSpec drafts a tree of candidate tokens in one pass, turning a bigger draft budget into longer accepted runs — up to 9.64× faster decode.

OpenAI and Broadcom's Jalapeño, a custom inference ASIC — Inference ASIC vs GPU — What does it mean?
OpenAI and Broadcom's Jalapeño runs LLM inference only, trading a GPU's flexibility for a shorter, faster path from memory to compute.

Routing, voting, and mixture-of-agents hit a shared ceiling across 67 models — Co-failure ceiling — What does it mean?
When every model misses the same question, no router, vote, or mixture-of-agents can recover it — and that shared-failure rate is ~2.5× higher than correlation predicts.

WorldKV — Evict-and-reinsert KV memory — What does it mean?
WorldKV evicts KV chunks to camera-indexed storage and reinserts them on revisit, bounding a video world model's cache at ~2x throughput.

MiniMax-M2 ships a 230B open MoE with 40× faster RL training — Forge RL prefix-tree merging — What does it mean?
MiniMax-M2's Forge RL merges rollouts that share an opening into one tree, so the shared work runs once — a reported 40× training speedup.

Agentic CLEAR grades agents at three zoom levels (IBM) — System/trace/node eval granularity — What does it mean?
Agentic CLEAR reads traces your agent already logs and writes an LLM-judge diagnosis at three zoom levels: node, trace, and system.
Grouped Query Experts puts mixture-of-experts routing inside attention — Query-head expert routing — What does it mean?
Grouped Query Experts adds a per-token router that turns on only a few of attention's query heads — keeping every key-value head dense, so the KV cache is unchanged.

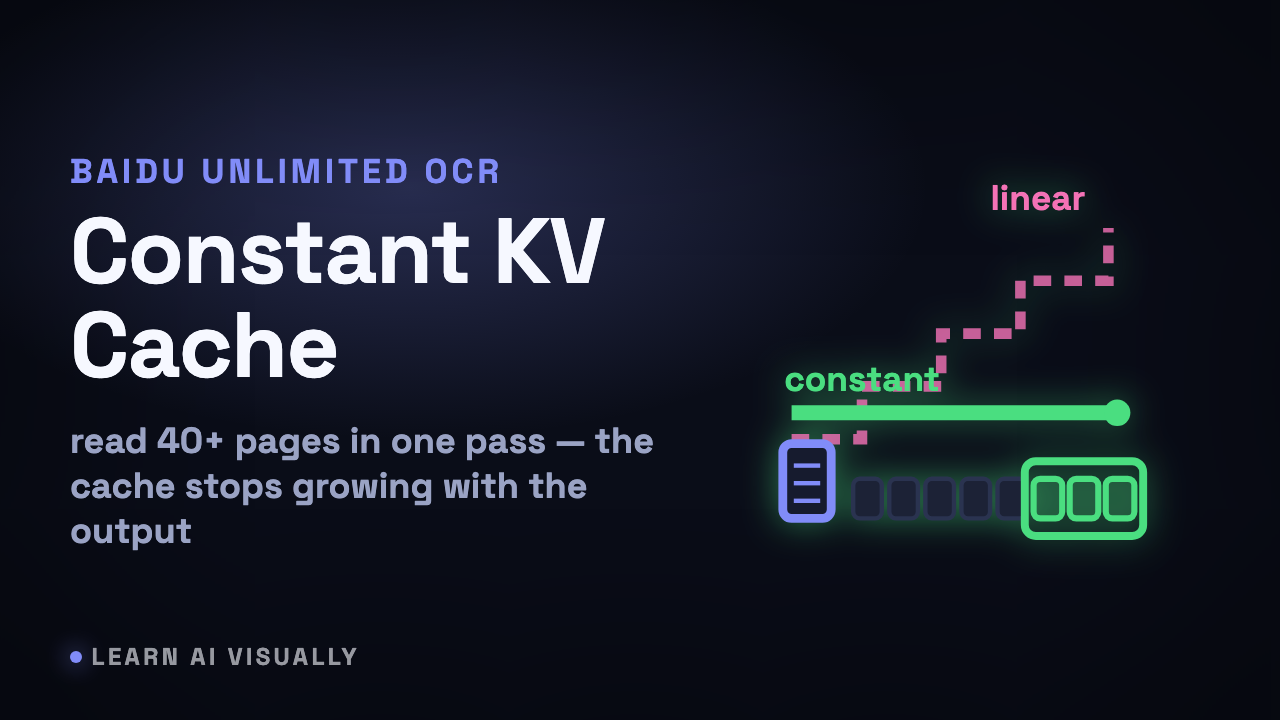
Baidu Unlimited OCR holds the KV cache constant for 40+ pages — Reference Sliding Window Attention — What does it mean?
Baidu's Unlimited OCR swaps decoder attention for R-SWA — each token reads the whole document plus only the last 128 outputs — so the KV cache stays constant across 40+ pages.